Keepalived和Heartbeat
Keepalived
1.Keepalived使用更简单:从安装、配置、使用、维护等角度上对比,Keepalived都比Heartbeat要简单得多,
尤其是Heartbeat 2.1.4后拆分成3个子项目,安装、配置、使用都比较复杂,尤其是出问题的时候,都不知道具体是哪个子系统出问题了,
而Keepalived只有1个安装文件、1个配置文件,配置文件也简单很多
2.Heartbeat功能更强大:Heartbeat虽然复杂,但功能更强大,配套工具更全,适合做大型集群管理,而Keepalived主要用于集群倒换,基本没有管理功能
3.协议不同:Keepalived使用VRRP协议进行通信和选举,Heartbeat使用心跳进行通信和选举,Heartbeat除了走网络外,还可以通过串口通信,貌似更可靠
4.使用方式基本类似:如果要基于两者设计高可用方案,最终都要根据业务需要写自定义的脚本,Keepalived的脚本没有任何约束,随便怎么写都可以,Heartbeat的脚本有约束,
即要支持service start/stop/restart这种方式,而且Heartbeart提供了很多默认脚本,简单的绑定ip,启动apache等操作都已经有了
使用建议:优先使用Keepalived,当Keepalived不够用的时候才选择Heartbeat
ubuntu 配置VIP
|
|
keepalived install
|
|
keepalived config
|
|
global_defs
notification_email: keepalived在发生诸如切换操作时需要发送email通知地址,后面的 smtp_server 相比也都知道是邮件服务器地址。也可以通过其它方式报警,毕竟邮件不是实时通知的。
router_id: 机器标识,通常可设为hostname。故障发生时,邮件通知会用到
vrrp_instance
state: 指定instance(Initial)的初始状态,就是说在配置好后,这台服务器的初始状态就是这里指定的,但这里指定的不算,还是得要通过竞选通过优先级来确定。如果这里设置为MASTER,但如若他的优先级不及另外一台,那么这台在发送通告时,会发送自己的优先级,另外一台发现优先级不如自己的高,那么他会就回抢占为MASTER
interface: 实例绑定的网卡,因为在配置虚拟IP的时候必须是在已有的网卡上添加的
mcast_src_ip: 发送多播数据包时的源IP地址,这里注意了,这里实际上就是在那个地址上发送VRRP通告,这个非常重要,一定要选择稳定的网卡端口来发送,这里相当于heartbeat的心跳端口,如果没有设置那么就用默认的绑定的网卡的IP,也就是interface指定的IP地址
virtual_router_id: 这里设置VRID,这里非常重要,相同的VRID为一个组,他将决定多播的MAC地址
priority: 设置本节点的优先级,优先级高的为master
advert_int: 检查间隔,默认为1秒。这就是VRRP的定时器,MASTER每隔这样一个时间间隔,就会发送一个advertisement报文以通知组内其他路由器自己工作正常
authentication: 定义认证方式和密码,主从必须一样
virtual_ipaddress: 这里设置的就是VIP,也就是虚拟IP地址,他随着state的变化而增加删除,当state为master的时候就添加,当state为backup的时候删除,这里主要是有优先级来决定的,和state设置的值没有多大关系,这里可以设置多个IP地址
track_script: 引用VRRP脚本,即在 vrrp_script 部分指定的名字。定期运行它们来改变优先级,并最终引发主备切换。
vrrp_script
告诉 keepalived 在什么情况下切换,所以尤为重要。可以有多个 vrrp_script
script: 自己写的检测脚本。也可以是一行命令如killall -0 nginx
interval 2: 每2s检测一次
weight -5: 检测失败(脚本返回非0)则优先级 -5
fall 2: 检测连续 2 次失败才算确定是真失败。会用weight减少优先级(1-255之间)
rise 1: 检测 1 次成功就算成功。但不修改优先级
这里要提示一下script一般有2种写法:
通过脚本执行的返回结果,改变优先级,keepalived继续发送通告消息,backup比较优先级再决定
脚本里面检测到异常,直接关闭keepalived进程,backup机器接收不到advertisement会抢占IP
上文 vrrp_script 配置部分,killall -0 nginx属于第1种情况,/etc/keepalived/check_nginx.sh属于第2种情况(脚本中关闭keepalived)。个人更倾向于通过shell脚本判断,但有异常时exit 1,正常退出exit 0,然后keepalived根据动态调整的 vrrp_instance 优先级选举决定是否抢占VIP:
如果脚本执行结果为0,并且weight配置的值大于0,则优先级相应的增加
如果脚本执行结果非0,并且weight配置的值小于0,则优先级相应的减少
其他情况,原本配置的优先级不变,即配置文件中priority对应的值。
提示:
优先级不会不断的提高或者降低
可以编写多个检测脚本并为每个检测脚本设置不同的weight(在配置中列出就行)
不管提高优先级还是降低优先级,最终优先级的范围是在[1,254],不会出现优先级小于等于0或者优先级大于等于255的情况
在MASTER节点的 vrrp_instance 中 配置nopreempt,当它异常恢复后,即使它 prio 更高也不会抢占,这样可以避免正常情况下做无谓的切换
以上可以做到利用脚本检测业务进程的状态,并动态调整优先级从而实现主备切换。
在默认的keepalive.conf里面还有 virtual_server,real_server 这样的配置,我们这用不到,它是为lvs准备的。notify可以定义在切换成MASTER或BACKUP时执行的脚本。
virtual_router_id:如果一个网段内有多个VIP地址的话,这个值不能相同,否则会报one or more VIP associated with VRID mismatch actual MASTER advert
实例图
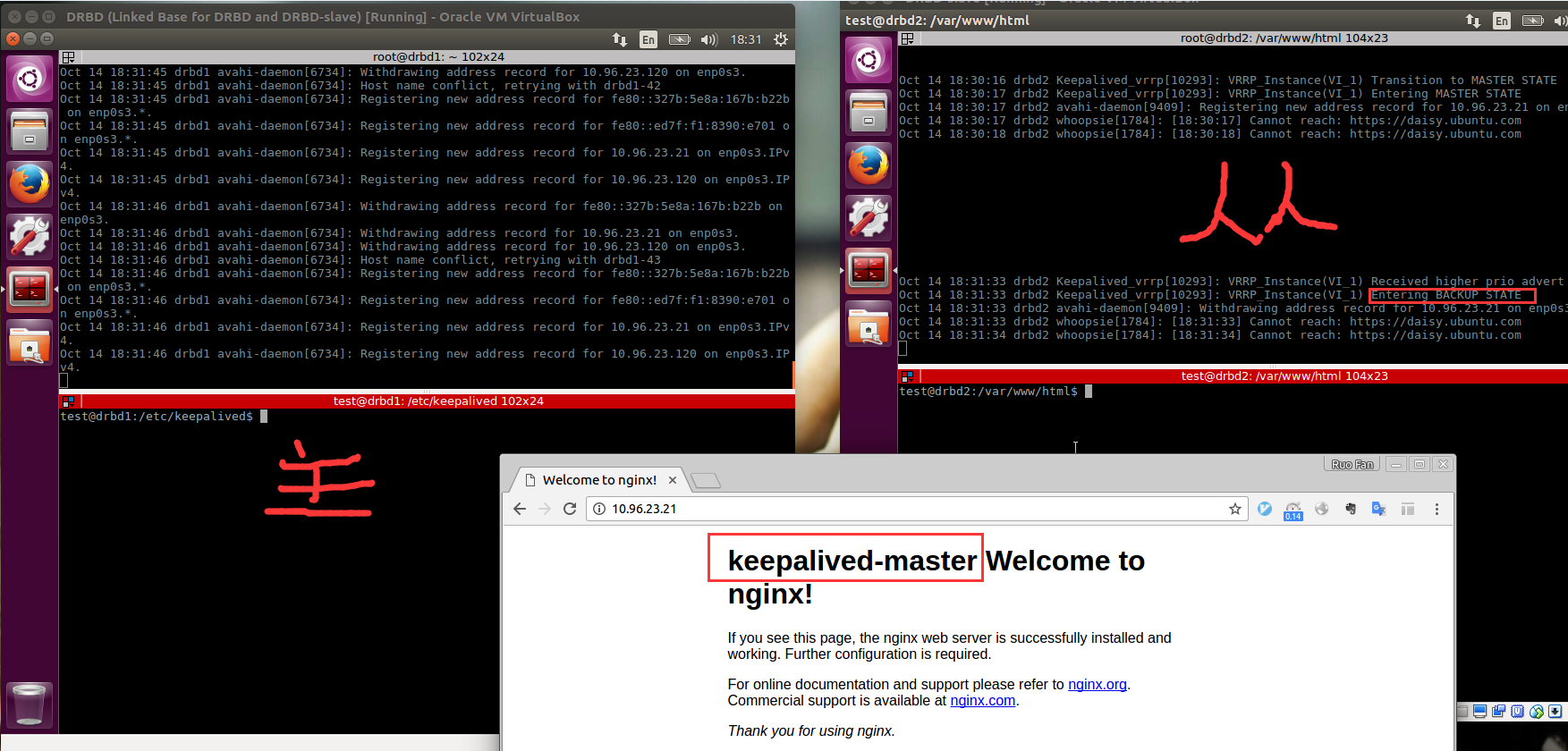
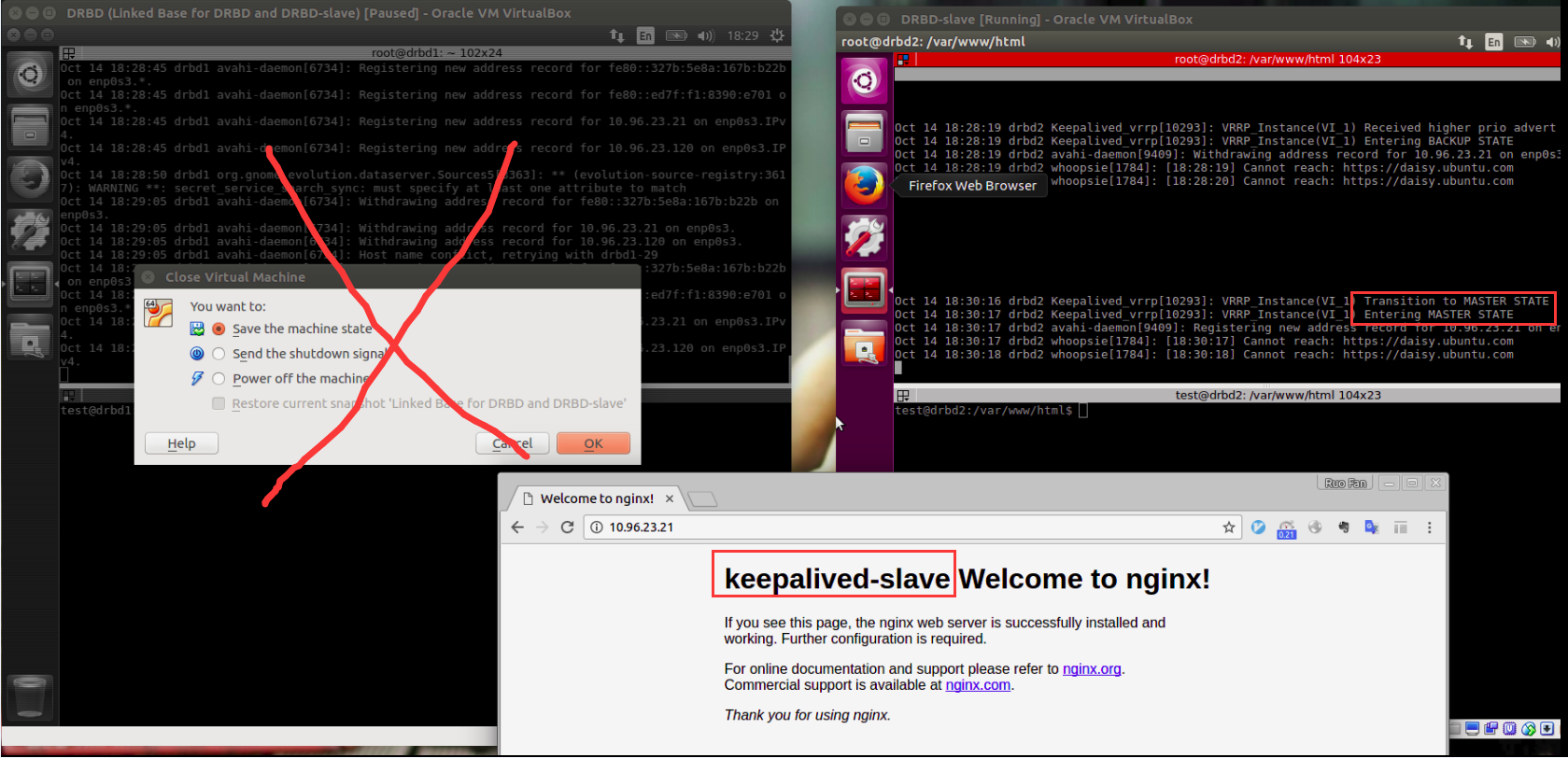
参考
High Availability Support Based on keepalived
LVS原理详解及部署之五:LVS+keepalived实现负载均衡&高可用